City Models are Too Simple
Cities are complex. Yet, we don’t think about them that way.
For centuries we have looked for simple abstractions of cities, such as Price’s analogy of the city to three types of egg: boiled, poached and scrambled — in that chronological order.
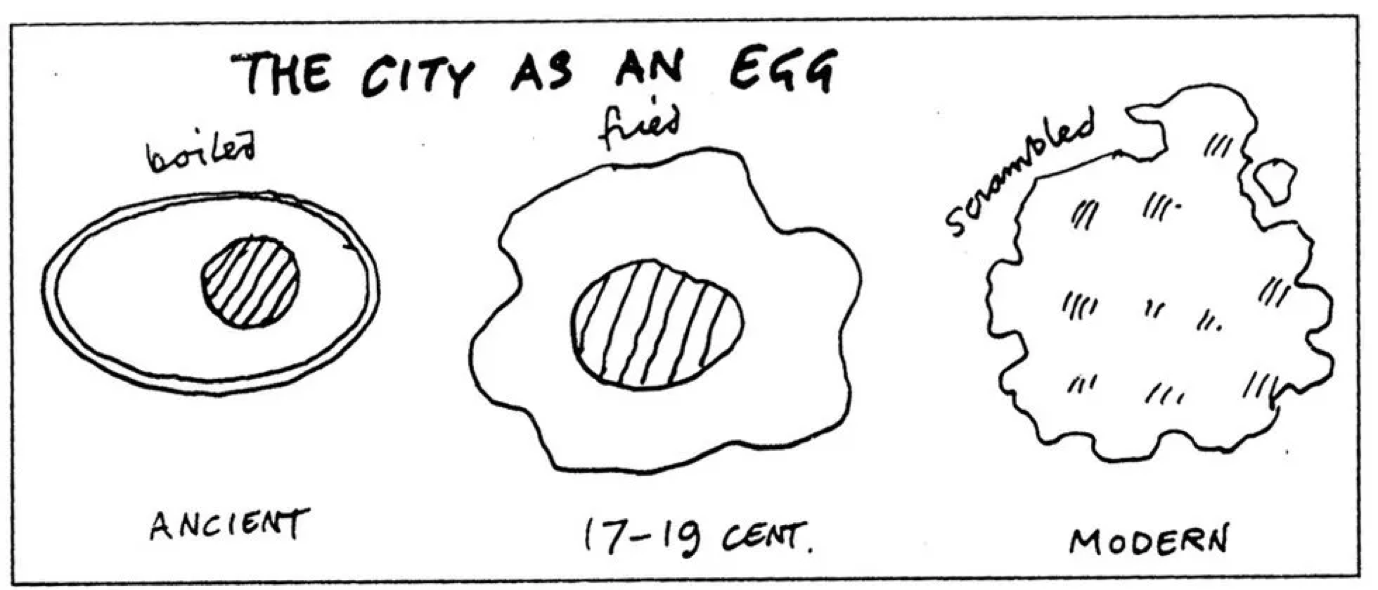
by Cedric Price (1934–2003).
Price’s egg model was a useful abstraction of the city until the end of the 19th century, when the city was concentrated in a dense compact centre. However, as the modern city started to resemble a scrambled egg, the egg analogy lost its popularity.
Modern cities no longer follow Price’s egg analogy.
Deep Learning Comes to the Rescue
With more and more data on urban forms, we have a unique opportunity to push the frontiers of urban modelling towards more accurate urban models. How so? The key to our approach lies in deep generative models.
Deep generative models are one of the most promising approaches towards building an understanding of complex phenomena, such as cities.
To train a generative model we first collect a large amount of data (in our case thousands of urban street images) and then train a model to generate data like it. The intuition behind this approach follows a famous quote from Richard Feynman:
“What I cannot create, I do not understand” — Richard Feynman
The trick is that the neural networks we use as generative models have a number of parameters that is substantially lower than the amount of data that we train them on, so the models are forced to learn the essence of urban forms in order to generate them.
Generative models hold the potential to automatically learn the natural features of the dataset, whether categories or dimensions or something else entirely. We firmly believe that if we learn the natural categories of modern cities, we can start to build accurate models of urban dynamics and evolution in time.
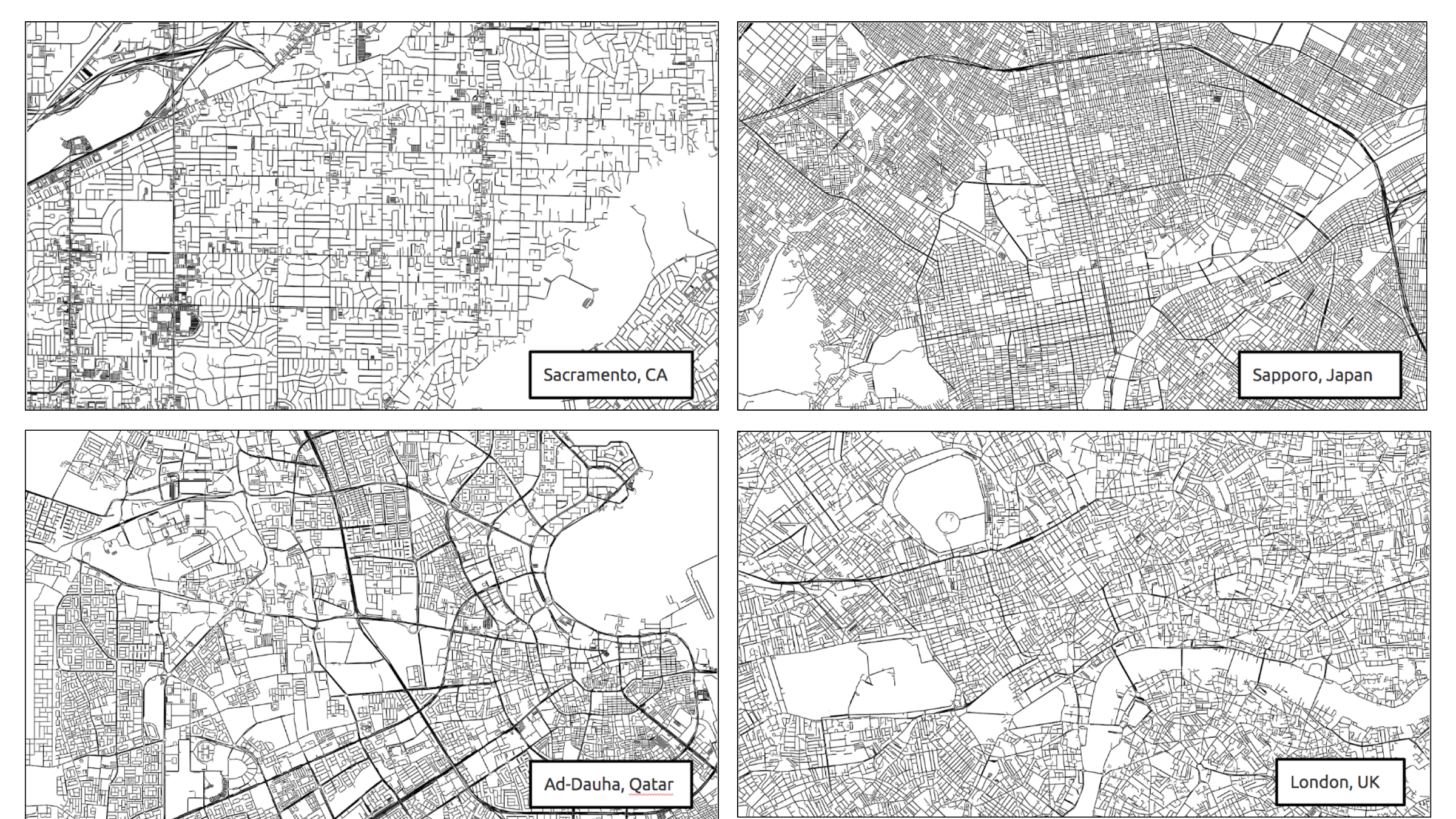
Generating urban images
We downloaded street networks of 13,000 biggest cities from OpenStreetMap by ranking world cities by 2015 population from the Global Human Settlement database. We then saved them as images and extracted a 3x3km sample from the centre of each image and resized it to a 64x64 pixels binary image to arrive at 13,000 urban images of the same size and spatial scale. Here are a few example images from this dataset:

Real street network examples.
Deep generative model
We then trained a Variational Autoencoder (VAE) on the urban street images. VAE is one of the most popular generative models. It consists of an encoder, a latent vector, and a decoder. The encoder takes an image as input and condenses it into a low-dimensional vector, known as the latent space. The decoder does the opposite, taking the latent vector and trying to reconstruct the original image.
VAE was particularly appealing for us because it learnt to compress street images into a lower-dimensional representation (latent vector). We could use the latent vector for quantitative comparisons and new street image generation.

Variational Autoencoder (VAE) architecture. VAE condenses urban images to a low-dimensional latent space (shown in purple).
Clustering Cities
Firstly, we used the latent vectors to cluster similar urban forms. We applied the K-means clustering algorithm and obtained street network clusters with distinct characteristics, such as density, spatial arrangement or road shapes.
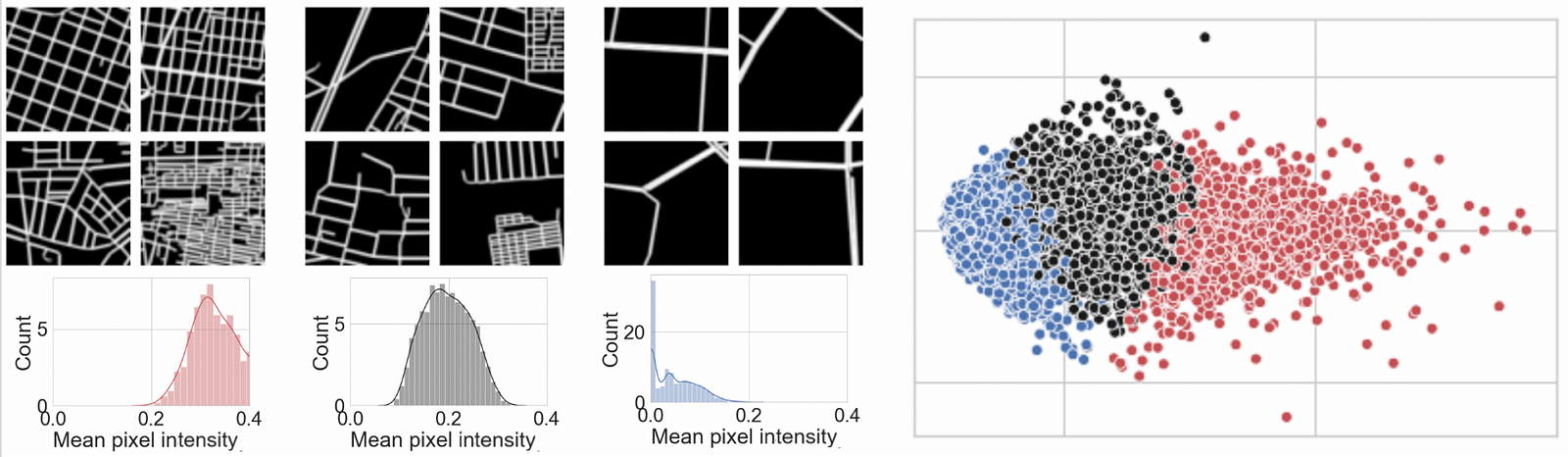
K-means clustering (with K=3) applied to the latent urban network vectors.

K-means clustering with K=6 applied to the same latent urban vectors.
Generating new urban forms
We also asked the VAE to ‘dream’ new urban forms by propagating a randomly sampled latent vector through the decoder network. The results, although not as sharp as real images, are first steps towards automated design of new realistic urban forms.

‘Deep Dreams’ of urban forms by VAE
Please let us know if you have any feedback on our work so far, or if you can think of other exciting applications of deep generative models!
You can learn more about our project by reading our paper and visiting our Github Repo.
