Time Series LLMs
Generative Large Language Models (LLMs) such as ChatGPT, Claude, and Google Bard have taken the world by storm, for better and worse. Students write essays faster than ever, and employees are made more productive at their jobs. However, models can be inaccurate and prone to hallucinations (i.e. making things up), and questions remain as to how researchers can reduce the massive energy requirements to train and run more advanced LLMs. Despite these drawbacks, models continue to grow in speed and accuracy. Gemini Flash is a remarkably fast model that generates outputs in seconds, while OpenAI’s o1 model can reason over its own ‘thoughts’ to provide a more accurate answer.
LLMs are typically used for chatting or instructional tasks like coding or generating formatted data. However, nascent research into other applications has yielded interesting and potentially state of the art results. Time series analysis is one of these applications. Time series data can be any observation measured over time, such as the Co2 levels in a room or the moisture levels of a house plant. Time series analysis uses a range of techniques and practices from simple linear regression to advanced deep learning to predict outcomes and identify patterns in data. Most interestingly, recent research from a variety of sources has shown that the self-attention properties of LLM transformer architectures are especially effective when analysing time-based data.
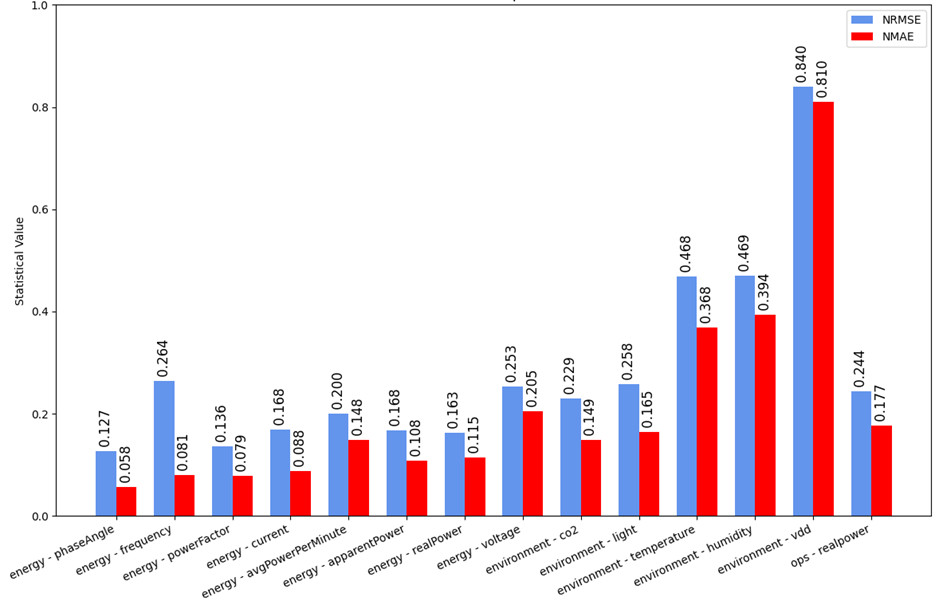
Time series data from UCL’s One Pool Street campus in Stratford, London
However, the real-world performance of LLMs for time series is still unclear. UCL’s Connected Environments team has been investigating the application of LLMs for time series analysis for the TRUST2 Portakabin management project. Portakabins are temporary, prefabricated buildings for construction sites, as offices, or as educational facilities, among other uses.

UCL’s Portakabin as an educational facility
As a part of the TRUST2 project, UCL has installed sensors in its Bloomsbury campus Portakabin to measure temperature, energy usage, people count, and other data points. Using LLMs to both predict usage and control unexpected changes in temperature or energy could lead to cost savings and better occupant comfort, not to mention the environmental effects of preventing wasted energy.

Interior shot of Portakabin sensors
Experiments
For the first part of this project, research work focused on benchmarking a comparative set of results from three time series LLMs. The goal of this phase was to verify the efficacy of LLMs for producing accurate time series forecasts, and to compare models based on ease of use, maintainability, accuracy, and applicability to the project. The models selected were:
Experiments were conducted using three datasets:
- Energy data from the Portakabin.
- Environmental data from the Portakabin.
- Building data from UCL’s One Pool Street campus.
First, a Python-based processing pipeline was written in Jupyter Notebooks to clean incoming Portakabin data. Several stages of cleaning and transformation were required to get data into an acceptable format for the LLMs, including removing redundant information, setting custom sampling rates for higher density data, and adding multithreaded functions to improve the speed of the pipeline. Over 8 million data points were processed for this set of experiments.
Data pipeline in Jupyter Notebooks
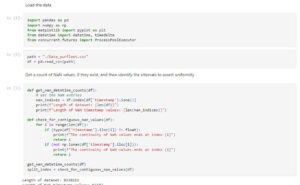
The first model, Amazon Chronos, displayed generally strong results when measuring the Normalised Root Mean Squared Error (NRMSE) and Normalised Mean Average Error (NMAE). Chronos does not require any model fine-tuning (the process of training an existing model with custom data), but instead forecasts out-of-the-box on input data.
Chronos NRMSE and NMAE values (lower is better)
However, as forecasting length was increased, accuracy dropped dramatically. The chart below shows different ratios of input data to output forecasts. Longer forecasts (e.g., 50% of data) were less accurate than those conducted with a higher input data ratio.
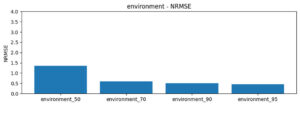
Chronos Environment NRMSE over forecast length (lower is better)
The other two models were not like Chronos, instead requiring fine tuning on the data used in experiments. A corollary of this is that Chronos was far easier to use, with a well-maintained codebase that did not require the complexity of custom data tuning to work. Furthermore, it comes with Apple Silicon support. However, fine tuning LLM4TS led to more consistent results, as shown below.
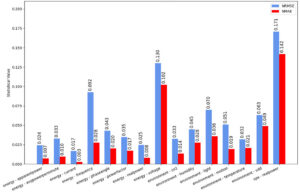
LLM4TS NRMSE and NMAE values (lower is better)
Generally, LLM4TS demonstrated excellent accuracy over the datasets. The process of fine-tuning took about a day on a PC with two RTX 4090s, but clearly yielded better results. This phenomenon highlights an interesting decision when forecasting with time series LLMs. Off-the-shelf models may be faster to forecast. However, taking time to build a data pipeline and fine-tuning a model could allowing more accurate forecasting.
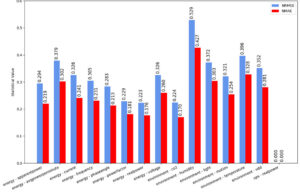
TEMPO NRMSE and NMAE values (lower is better)
The last model, TEMPO, performed worse than LLM4TS on fine-tuned data sets. It is possible that getting better results from TEMPO would require pretraining on the same datasets used in the research paper, such as the ETT set. Retraining on these data sets may be a part of a future experiment but could not be completed in time for this phase of research.
Transformer models – more than meets the eye?
LLMs appear to demonstrate some innate knowledge about the behaviours of data sets outside of natural language text. This begs the question: what other areas of application could LLMs benefit? What other knowledge is being trained into the latent spaces of model values? LLMs have received their fair share of criticisms – for example, these latent spaces may at times be nonsensical. However, the above experiments show that at least in time series analysis, results can be equal to – or even better than – the alternatives.
The next steps for this project include training these LLMs to perform anomaly detection (e.g., to detect when temperatures are unusually high or low). A combination of forecasting and anomaly detection could allow a chat bot LLM to make informed decisions and manage building resources through Retrieval-Augmented Generation (RAG) (see an early prototype we developed, below). As CASA continues to experiment with LLMs for time series data, we’ll update our findings on this blog. For now, those interested in this subject can find further academic reading material here.
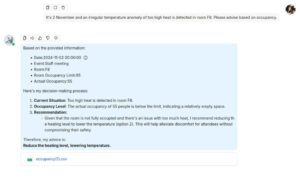
An early prototype of a RAG-enabled LLM for time-series based decision support
